从排名到评分
我们在 Meilisearch 搜索结果中添加相关性评分的历程。

欢迎来到文字自助餐!请点餐,我们将为您奉上最优质的20份文档,它们与您的查询最匹配!好吧,我们说优质,但我们不会确切告诉您*它们与您的查询匹配得有多好*,我们只向您保证它们是我们现有最好的。您说这无法接受?您是该地区最著名的餐厅评论家,您需要能够区分完美匹配和一堆乱七八糟的词,您是这么说吗?哦,那听起来确实是个麻烦……

Meilisearch 是一个开源搜索引擎,旨在提供闪电般快速、高度相关的搜索,且集成工作量极小。它允许将文档以称为索引的组存储在磁盘上,并搜索这些索引以获取与每个查询相关的文档。顺便说一句,如果您想让生活更轻松,专注于您提供的搜索体验,我们提供了一个云解决方案,它始终受益于我们的最新版本😉
在最近 [1.3 版本发布](/blog/v1-3-release/)之前,Meilisearch 无法得知文档与特定搜索查询的匹配程度。本文深入探讨了我们添加此功能的历程。
动机
为文档提供相关性评分服务于许多高度请求的使用案例
- 根据文档评分调整搜索结果的呈现方式。例如,开发者 bakerfugu 有一个日历应用程序,他希望通过颜色区分来突出会议和活动的相关性。然而,搜索结果的顺序不足以满足需求,因为即使是排名靠前的结果,其相关性也可能有所不同。如果没有评分,我们只知道它是 Meilisearch 能找到的最佳结果。
- 实现聚合搜索。聚合搜索是一种将来自搜索多个索引的结果显示为针对单个统一索引执行搜索的方式。用户在多个 GitHub 讨论中报告了实际使用案例。
- 实现分片。分片类似于联合搜索,它结合了多个搜索查询的结果。与联合搜索不同,分片涉及在多个 Meilisearch 实例上查询分区索引,而不是在同一实例中查询多个索引。数据预计会更同质化,但必须能够在查询完成后进行重新排序,可以说是在“离线”状态下。
- 理解相关性。Meilisearch 使用一组预定义规则对文档进行排名。通过为每个排名规则生成详细评分,可以更精细地了解各个规则如何应用于特定查询的文档。这有助于发现最大化每个使用案例相关性的最佳设置。
从这四个使用案例中可以看出,实现评分功能的设计空间很大。解决方案应具备哪些特性才能最好地解决所有这些使用案例?让我们来看看它们。
目标特性
从不同的使用案例中,我们可以看到多个不同的用户群和使用方式。我们确定了两个轴线,可以沿着这两个轴线提供多种解决方案。
- 聚合评分与详细评分。对于日历使用案例,每个文档的单个“聚合”评分就足够了,而要理解相关性,则需要每个排名规则的详细评分。理想的解决方案应提供聚合评分和详细评分。
- 机器可读与人类可读。大多数使用案例需要集成或前端能够自动处理的信息。然而,如果我们的目标是使相关性更容易理解,我们需要提供人类可读的信息。因此,解决方案应该在这两个特性之间取得适当的平衡。
此外,为了实现聚合搜索和分片,评分必须独立于所搜索索引中包含的文档。事实上,如果向索引添加文档会改变其他文档的评分,那么将该评分与包含不同文档的另一个索引进行比较就毫无意义。
最后,我们希望评分系统是直观的:Meilisearch 应该按照最小惊讶原则,以相关性评分递减的顺序返回文档。
特别是最后这个特性,使我们倾向于一种基于 Meilisearch 已执行排名的解决方案,以此来保证排名和评分之间的一致性。
总之,解决广泛的使用案例需要一个评分功能,它不仅提供聚合评分和详细评分,还要兼顾机器和人类可读性。它还应保持评分独立性,不受搜索索引中文档的影响,并与 Meilisearch 现有的排名系统保持一致。要了解我们如何基于排名构建此评分系统,我们首先需要了解排名本身。
递归桶排序
本节介绍 Meilisearch 如何根据搜索查询对文档进行排名。如果您已经了解 Meilisearch 使用的递归桶排序算法,可以跳过本节。此外,由于本节主要关注搜索算法,因此不涉及引擎的其他部分,例如索引。如果您对这些内容感兴趣,我们之前在一篇[专门文章](/blog/how-full-text-search-engines-work/)中介绍过它们。
Meilisearch 的核心是使用一种称为“桶排序”的算法。它根据一组排名规则将文档排序到不同的桶中。第一个排名规则适用于所有文档,而每个后续规则仅作为平局决胜器应用于在桶内被视为相等的文档。当所有“最内层”桶包含单个文档时,或者在应用最后一个排名规则后,排序完成。
例如,words 排名规则根据文档中找到的查询词数量对文档进行排序。如果多个文档最终落在同一个桶中,则使用另一个排名规则(如typo)来区分它们。
对于查询“Badman dark knight returns”,words 排名规则将把返回的文档分成4个桶,从包含所有单词(可能带有拼写错误)的文档到只包含“Badman”的文档。typo 排名规则帮助我们进一步区分最后一个桶中的文档。
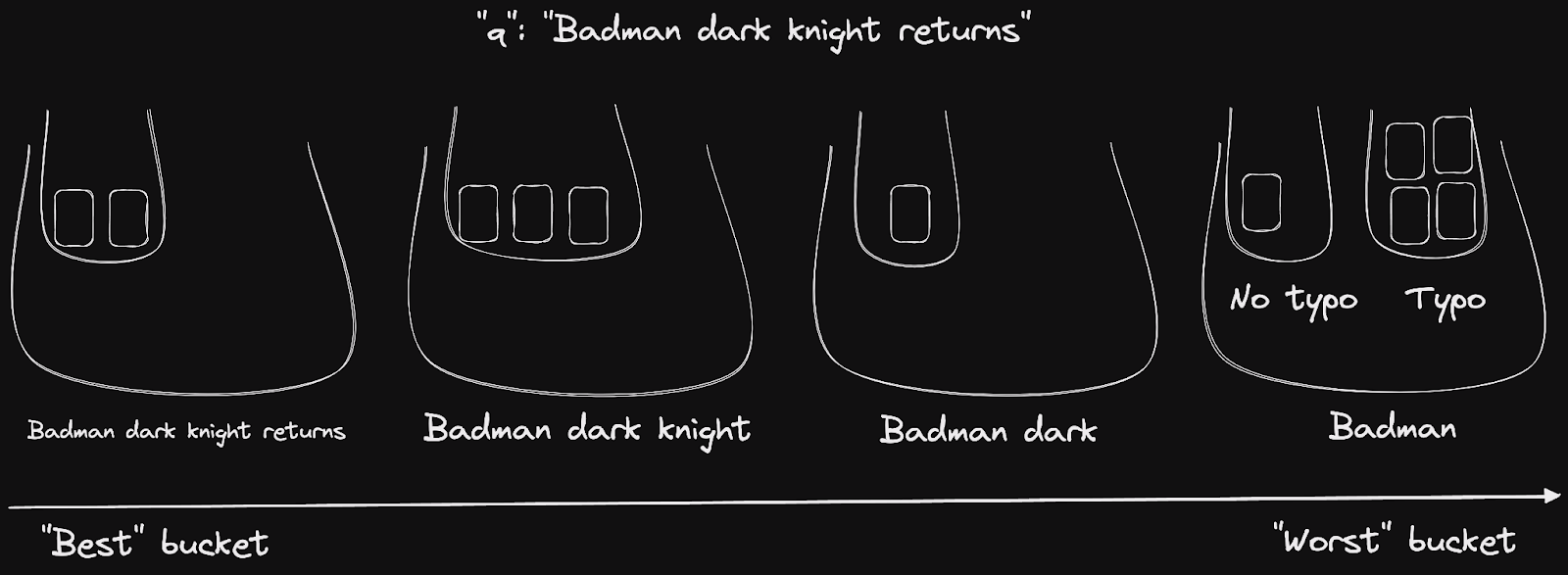
👉 请注意,此规则对其他三个桶没有影响,因为它们只包含查询存在拼写错误“Badman -> Batman”的文档。
现在我们已经很好地理解了 Meilisearch 对文档进行排名的方式,让我们回顾一下我们对评分功能的期望特性:
- 它应该提供聚合评分和详细评分
- 它应该兼顾机器可读性和人类可读性
- 它应该保持评分独立性,不受搜索索引中文档的影响
- 它应该与 Meilisearch 现有的排名系统保持一致。
我们如何扩展 Meilisearch 的排名行为以生成满足这些标准的评分?我们接下来将探讨这一点。
从排序到评分
根据我们刚刚学到的,每个排名规则将整个数据集分成若干个桶,然后按顺序返回它们。然后,我们可以使用每个桶的排名以及每个规则的桶总数来计算评分,从而产生递归桶评分算法。

让我们重用我们之前的“badman”示例来实践。我们计算words 桶的数量为4,对于这些桶中的每一个,计算内部typo 桶的数量。我们得到了下面图示的内容。
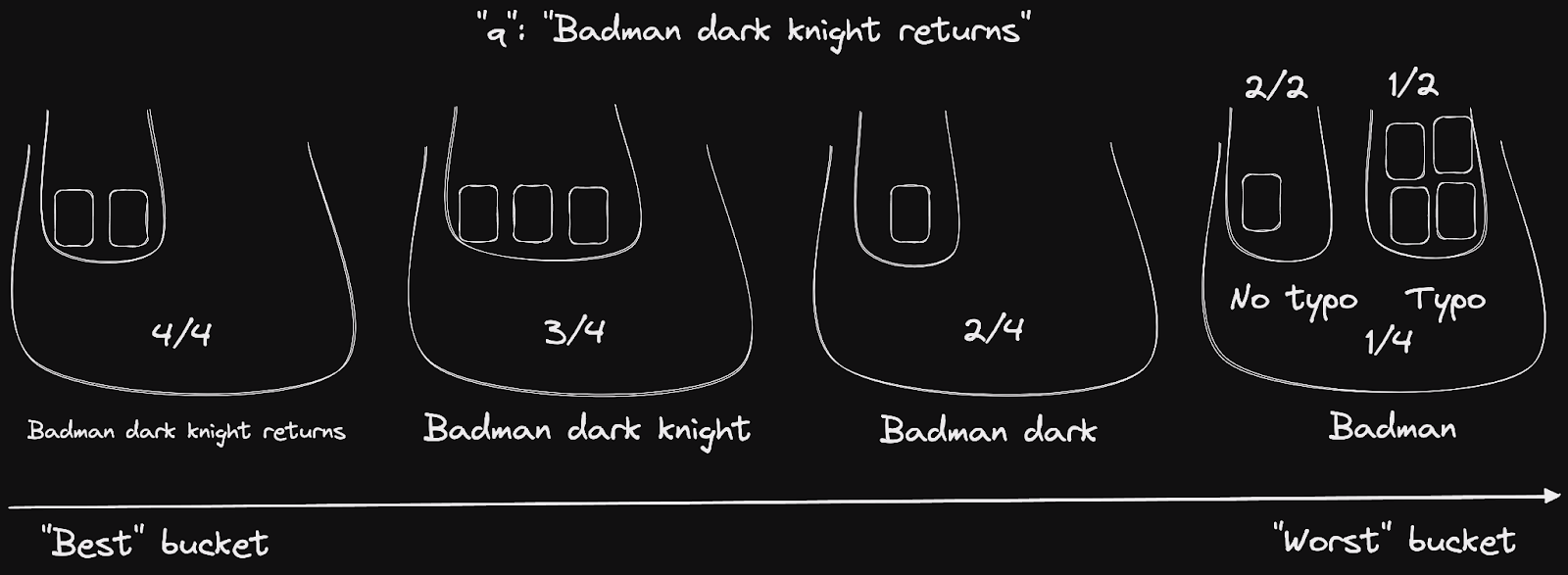
文档桶,用小数评分标记
通过对 sample movies.json 数据集的查询应用递归桶排序,我们得到了以下排名。为简单起见,我们已将数据集配置为只有标题是可搜索属性,这使得结果更容易理解。有了这个,我们能够为每个文档分配一个由两个组件组成的详细评分,结果如下:
| 单词与拼写错误评分 | 电影标题 |
|---|---|
words 4/4,typo 1/1 | - 蝙蝠侠:黑暗骑士归来(上) |
| - 蝙蝠侠:黑暗骑士归来(下) | |
words 3/4, typo 1/1 | - 蝙蝠侠揭秘:黑暗骑士的心理学 |
| - 黑暗骑士传奇:蝙蝠侠的历史 | |
words 1/4, typo 2/2 | - 天使与恶人 |
words 1/4, typo 1/2 | - 蝙蝠侠:第一年 |
| - 蝙蝠侠:红影迷踪 |
这为我们按排名规则获得的详细评分提供了初步形式,尽管我们可能希望用规则特定的语义信息(例如匹配词的数量和拼写错误的数量)来增强评分。
我们尚未探讨如何从这些详细评分中为每个文档生成单一评分,如何确保其独立于数据集,以及如何处理排序规则的特殊情况。
那么,我们如何将这些适用于高级使用场景的复杂评分,转化为每个文档的单个聚合评分,以满足那些不需要如此高细节水平的使用场景呢?我们将在下一节中讨论。
聚合评分
为了保持评分系统的直观性,聚合评分必须与 Meilisearch 给出的排名保持一致。请记住,后续排名规则主要用于解决先前规则产生的平局。同样,后来的排名规则只应细化从先前规则得出的评分。
考虑到这一点,让我们修改之前的图表。与其将匹配所有词的words 桶标记为“4/4”,不如说这个桶中的文档落在3/4到4/4的范围内。我们将让typo 排名规则来精确决定它们落在哪里。我们只考虑最后一个words 桶,因为它有两个typo 内部桶。
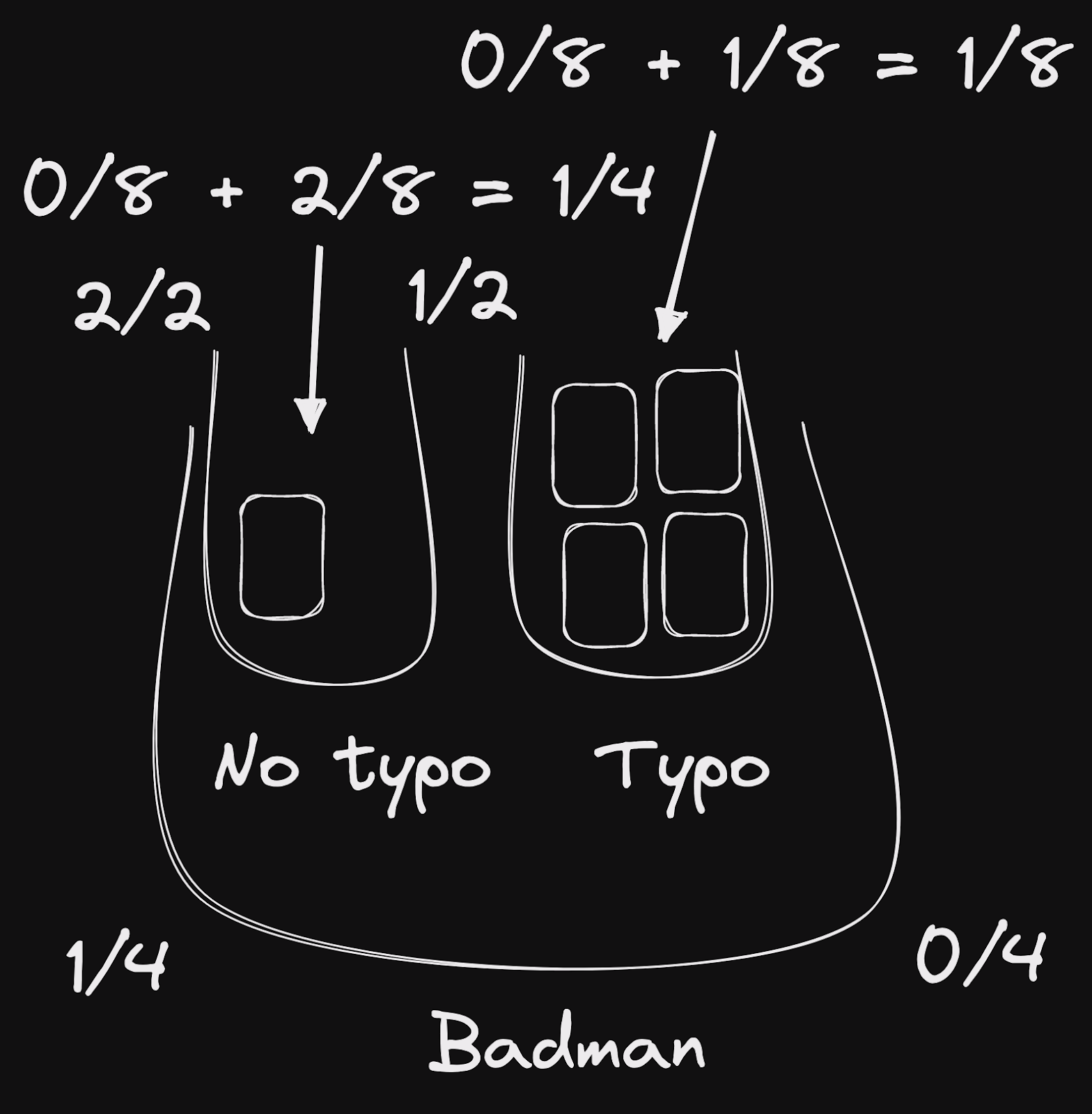
这样,我们就可以计算每个文档的聚合评分
words4/4,typo1/1: 1.0words3/4,typo1/1: 0.75words1/4,typo2/2: 0.25words1/4,typo1/2: 0.125

上述内容提供了对评分的直观理解,但在具体实现时需要注意细节。特别是,我们只为3个最佳words 桶设置了一个typo 桶,因为在我们的索引中,没有文档落在这些words 桶中且对“Batman”没有拼写错误。
现在,如果我们添加一部名为“The badman returns to the dark knight”的新电影会怎样?第一个words 桶现在有两个typo 桶,“Batman: the dark knight returns, part 1”不再是完美匹配:它的评分变为 0.875 而不是 1.0。我们需要避免这个问题。
实现数据集独立性
我们的评分应该完全独立于索引中包含的文档。每个规则都应该能够仅根据查询,而不是索引中的文档,计算出理论上的最大桶数。
对于typo 规则,这涉及将索引的拼写容错设置应用于查询并计算可能的最大拼写错误数量。默认设置通常允许五个或更多字符的词有1个拼写错误,以及至少九个字符的词最多有2个拼写错误。
在这些设置下,查询“Badman dark knight returns”最多允许3个拼写错误(“badman”1个,“knight”1个,“returns”1个),总共有4个可能的桶,从0到3个拼写错误。这意味着“Batman: the dark knight returns, part 1”的实际评分应该是 0.9375,无论“The badman returns to the dark knight”这部电影是否存在于索引中或任何地方(上面层级列表中的评分修正留给读者作为练习)。
幸运的是,对于大多数排名规则,计算理论上的最大桶数可以通过自然的方式完成(详细说明每种排名规则的方式超出了本文的范围,但如果您感兴趣,我们乐意解答😊)。不幸的是,sort 和 geosort 排名规则是显著的例外。
排序规则不影响评分
排序规则系列允许根据文档某个字段的值进行排序。
这就产生了一个问题。如果我们想要一个规则能返回的最大桶数,那么当按例如产品价格排序时,这个数字应该是什么?请记住,该值必须独立于索引中的文档。
我们在这里考虑了多种选择,例如根据值的分布自动推断各种桶,同时仍然允许开发者在评分时指定分桶方式。最终,我们选择了最简单的选项,一个不增加额外 API 表面积的选项:评分不受排序排名规则的影响。它们被视为返回单个桶。
这个决定会产生一些不匹配的阻抗,因为实际上,当使用排序排名规则时,Meilisearch 会将具有相同值的文档排在同一个桶中。这意味着,如果您的排名规则在根据拼写错误进行区分之前按价格升序排序,您将得到以下顺序:
- 价格为100美元的文档,无拼写错误
- 价格为100美元的文档,有拼写错误
- 价格为200美元的文档,再次无拼写错误
- 价格为200美元的文档,有拼写错误
由于排序排名规则不影响评分,返回在(2)中的文档的相关性评分将低于返回在(3)中的文档。毕竟,前者有拼写错误,而后者没有。这可能会让用户感到惊讶,也是我们本来希望避免但未能找到实用方法解决的问题。
另一种看待这个问题的方式可能会让它显得更自然。虽然大多数排名规则按相关性对文档进行排序,但按字段排序的排名规则是按该字段的值进行排序的,最终,只能有一种顺序。
总结一下,当使用聚合评分对文档进行排名时,任何按字段排序的排名规则的效果都会在排名中被抵消。当使用详细评分时,这不是问题,因为详细评分提供了用于按字段排序排名规则对文档进行排名的值,因此开发者在重新排名时可以考虑这些值。
使用评分 API
Meilisearch v1.3 允许在搜索请求中指定 showRankingScore 查询参数,将该参数设置为 true 会导致一个 _rankingScore 浮点值被注入到搜索返回的文档中。
然后可以获取每个文档的评分,例如,根据评分值选择不同的表情符号或 CSS 类。
| 评分 | 表情符号 |
|---|---|
| 0.99 | 👑 |
| 0.95 | 💎 |
| 0.90 | 🏆 |
| ... | ... |
| 0.25 | 🐓 |
我相信开发者会想出很多使用这个评分的方法,比我这个可怜的后端工程师的尝试更有想象力😳
Meilisearch v1.3 也公开了 _rankingScoreDetails。然而,由于它们增加了大量的 API 表面,目前它们被一个运行时实验性标志所限制。我们感谢您的反馈!
结论
实现相关性评分是 Meilisearch 针对一个设计空间庞大且复杂的功能所进行的设计过程的一个例子。
它也为良好的社区互动提供了一个绝佳的机会,因为我们发布了该功能的多个原型并从用户那里获得了反馈。我们特别感谢用户 @LukasKalbertodt,他对原型提供的宝贵反馈无疑帮助我们改进了解决方案 ❤️
我们使用评分 API 获得的早期结果非常有前景
- 调试相关性。Meilisearch v1.3 已经包含了相关性改进,这些改进通过详细评分揭示了相关性问题而变得显而易见。
- 解锁聚合搜索。使用聚合评分对来自异构搜索查询和索引的文档进行重新排名,从而解锁了聚合搜索的第一个版本。如果使用实验性功能开关启用详细评分,则可以更精细地对文档进行重新排名。
- 解锁混合搜索。相关性评分可作为实现混合搜索的一种手段,结合我们一直在做的[语义搜索](/blog/vector-search-announcement/)工作。
我们希望您喜欢这次对评分功能的深入探讨,并希望它对您有所帮助。欢迎在我们的 Discord 社区提供反馈。
如需了解更多 Meilisearch 相关内容,您还可以订阅我们的新闻通讯,查看我们的路线图,参与我们的产品讨论,从源代码构建或在云上创建项目。再见!

隆重推出 Meilisearch 下一代索引器:更新速度快4倍,存储空间减少30%
2024版索引器通过并行处理、优化的内存使用和增强的可观测性,彻底改变了搜索性能。查看我们最新版本中的新功能。

Meilisearch 通过二进制量化将嵌入索引速度提高7倍
通过在向量存储 Arroy 中实现二进制量化,已显著减少大型嵌入的磁盘空间使用和索引时间,同时保持了搜索相关性和效率。

Meilisearch 太慢了
在这篇博客文章中,我们探讨了 Meilisearch 文档索引器所需的增强功能。我们将讨论当前的索引引擎、其缺点以及优化性能的新技术。