您正在以智能方式建立索引吗?
将文档添加到 Meilisearch 是否耗时过长?了解如何加快索引过程。

如果您刚刚使用我们的快速入门指南中的电影数据集试用 Meilisearch,那么索引您的数据可能只用了几秒钟。但如果您处理的是更大的数据集,那么耗时可能会长得多。在本文中,我们将回顾最佳实践,帮助您高效地索引数据并加快索引过程。
明确您的需求
Meilisearch 以离散记录的形式存储数据,这些记录称为文档,每个文档都必须有一个唯一的标识符——即主键。文档被分组到称为索引的集合中。
为了提供即时搜索体验,Meilisearch 需要以多种方式存储和组织数据,以便以最有效的方式检索数据。因此,文档在可供搜索之前必须经过彻底处理。
Meilisearch 中每个索引大约有二十种数据结构,构建它们是索引过程中最耗时的部分。更改索引设置可能会使许多这些数据结构失效,并需要重新索引您的数据。因此,通常最好在添加文档之前定义索引设置。
可搜索属性
默认情况下,添加到 Meilisearch 的所有文档字段都是可搜索的。但是,“可搜索属性”列表中字段中存在的词语是需要最多数据结构的——确切地说,是十一种。加快索引的一个好方法是确保可搜索属性列表中的所有属性都是您真正希望用于匹配查询词语的属性。
举例来说,一个包含图片 URL 字段的文档。您可能希望向用户显示图片,但我怀疑用户是否有兴趣在 URL 中搜索查询词。别忘了,并非所有显示字段都需要是可搜索的!
在可搜索属性列表中指定实际需要的字段固然重要,但更重要的是避免在可搜索字段中出现无意义、随机或唯一的值。想象一下,那些数据库中充满了“https”、“www”、“com”或类似“I77lHE”的值——这在尝试查找特定产品或电影时根本没用 😱
说到这个:🤔唯一值……这是否让您想起什么?💡主键!这是您可以安全地从可搜索属性列表中移除的另一个字段。
幕后原理
为了更好地理解自定义可搜索属性索引设置的重要性,我们来看看可搜索属性所需的最大数据结构。在我们提到的十一种数据结构中,有三种构建时间最长:WORD_DOCIDS、WORD_POSITION_DOCID 和 WORD_PAIR_PROXIMITY_DOCIDS。
为了更好地理解每种数据结构的工作原理,我们将使用以下文档集作为示例
{ "id": 1, "description": "New York City is the most populous city in the USA" }, { "id": 2, "description": "New York was named in honor of the Duke of York" }, { "id": 3, "description": "Tel Aviv is the new most expensive city in the world" }
在 WORD_DOCIDS 中,每个词都与其包含该词的文档的主键相关联
“new” => [1, 2, 3]“york” => [1, 2]
在 WORD_POSITION_DOCID 中,键是词语及其在文档中的位置。与键关联的值是该词语占据相同位置的文档。在上述文档中,id 将是属性 0,description 将是属性 1
new(1,0) => [1, 2]:在文档 1 和 2 中,“new”这个词位于属性 1 的位置 0——它是属性description的第一个词。new(1, 4) => [3]:在文档 3 中,“new”位于属性 1 的位置 4。
最后,在 WORD_PAIR_PROXIMITY_DOCIDS 中,Meilisearch 跟踪索引中所有文档中词对之间的距离。词语必须在彼此的 8 个词之内才能被存储,因为距离更远的词语不被视为同一上下文的一部分,因此不相关。
在上述示例文档中,Meilisearch 将存储以下词对
newyork1 => [1, 2]newcity2 => [1]newcity3 => [3]
词对后附带的数字表示它们之间的距离
- 1 表示词语相邻
- 2 表示它们之间相隔一个词
- 3 表示它们之间相隔两个词
如您所见,每个新词都代表 Meilisearch 内部数据结构中的额外行。唯一 ID 或 URL 字符串之类的值可能会使数据库急剧增长——而且很可能是不必要的增长。
优化 Meilisearch 应该搜索哪些字段对于减少索引时间至关重要。它还可以提高相关性和搜索速度,因为结果不会被不相关的数据污染。
可过滤和可排序属性
某些字段不包含任何词语,但可能仍然对帮助用户找到所需结果至关重要。这类数据可能比常规的基于文本的搜索更适合用于过滤和排序。
可过滤属性是可以用作过滤器以优化搜索结果的属性。您可以使用它们来限制特定用户的搜索结果,或者创建分面搜索界面,允许用户根据自己选择的条件缩小结果列表。布尔类型的值是非常好的过滤器。
可排序属性是可以在搜索时用于排序的属性,它允许用户决定他们希望首先看到哪些文档。数值非常适合排序。
根据经验,如果您的数据集包含带有数值和布尔字段值的文档,请花时间评估它们是否可以作为可过滤或可排序属性列表的一部分。
排名规则
排名规则负责搜索结果的相关性。Meilisearch 包含六个内置排名规则
[ "words", "typo", "proximity", "attribute", "sort", "exactness" ]
您还可以将升序和降序的自定义规则添加到此列表
[ "words", "typo", "proximity", "attribute", "sort", "exactness", "price:asc" ]
与用于搜索时排序的可排序属性不同,自定义排名规则用于设置默认顺序。
如果您需要这种默认排序,最好提前配置。在文档已经索引后添加新规则将触发重新索引,并可能让您感到紧张!
精简数据并批量处理
只索引您真正需要的内容。数据库中的所有列都是必需的吗?数据集中的列越少,文档就越小。文档越小,它们的重量就越轻,到达 Meilisearch 的速度就越快,然后 Meilisearch 就能更快地处理它们。
Meilisearch 将连续的文档添加请求合并成一个批次并一起处理。这显著加快了索引过程。由于每个批次的最终大小将取决于 Meilisearch 在处理最新文档添加请求时收到的数据量,因此建议以组为单位发送文档,而不是逐个发送。
出于同样的原因,请考虑压缩您的数据。Meilisearch 支持 br、deflate 和 gzip 压缩方法。您可以在我们的文档中找到更多信息。
保持更新并及时反馈
使用最新稳定版 Meilisearch。新版本通常包含性能改进,可以显著提高索引速度。
如果您遇到任何索引问题,请向我们报告!这对改进产品至关重要!
不要相信我,相信数据
在创建一些基准测试时,引擎团队的软件工程师 Many 绘制了以下图表。请注意,索引时间高度依赖于机器(CPU、RAM)和数据集的大小:对于类似大小的数据集,您可能会获得不同的结果。
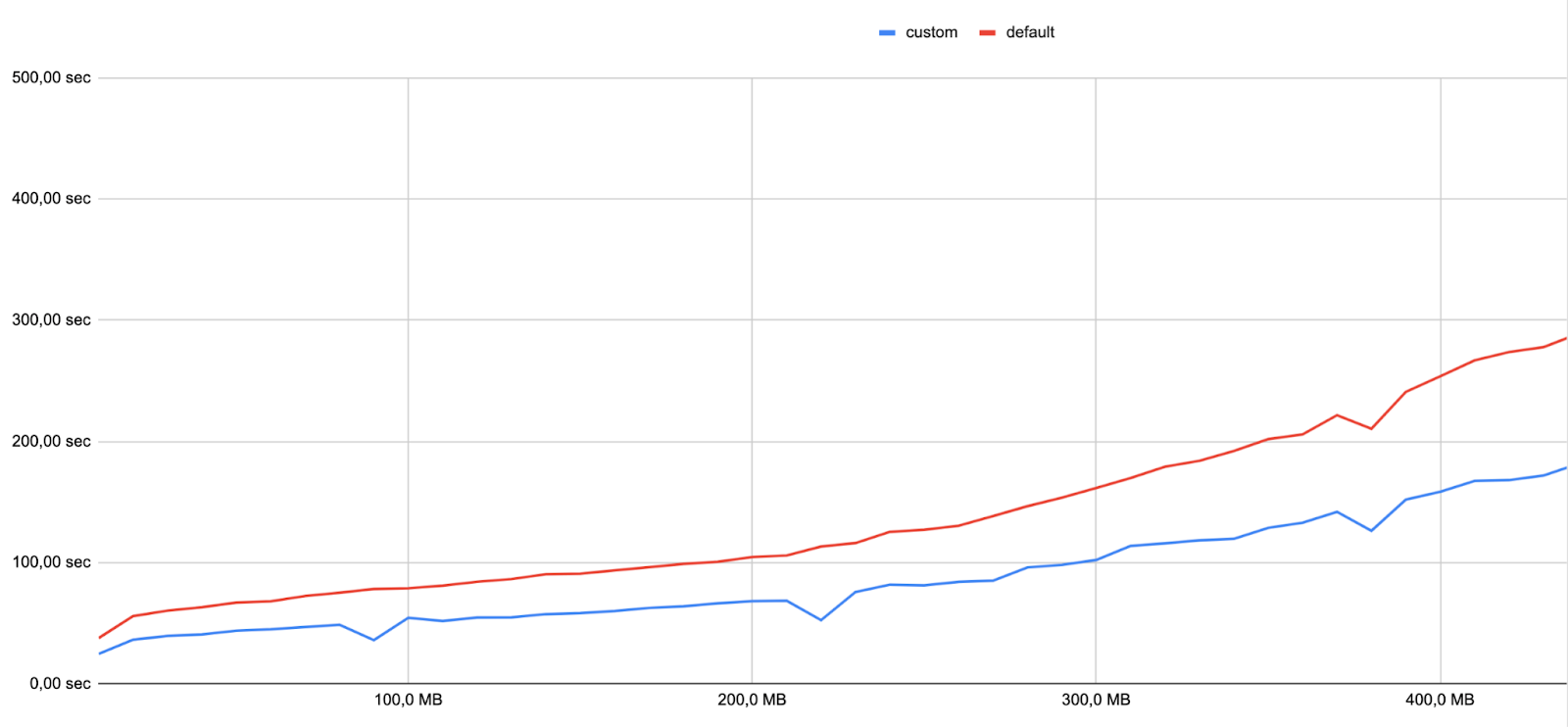
横轴表示数据集大小,纵轴表示索引时间
红线表示使用默认设置的索引时间,蓝线表示使用自定义配置的索引时间。在相同的机器和数据集下,我们观察到使用自定义设置时索引速度提高了 36%。
我们在数据库大小方面也观察到类似的改进,使用自定义设置时数据库大小显著减小
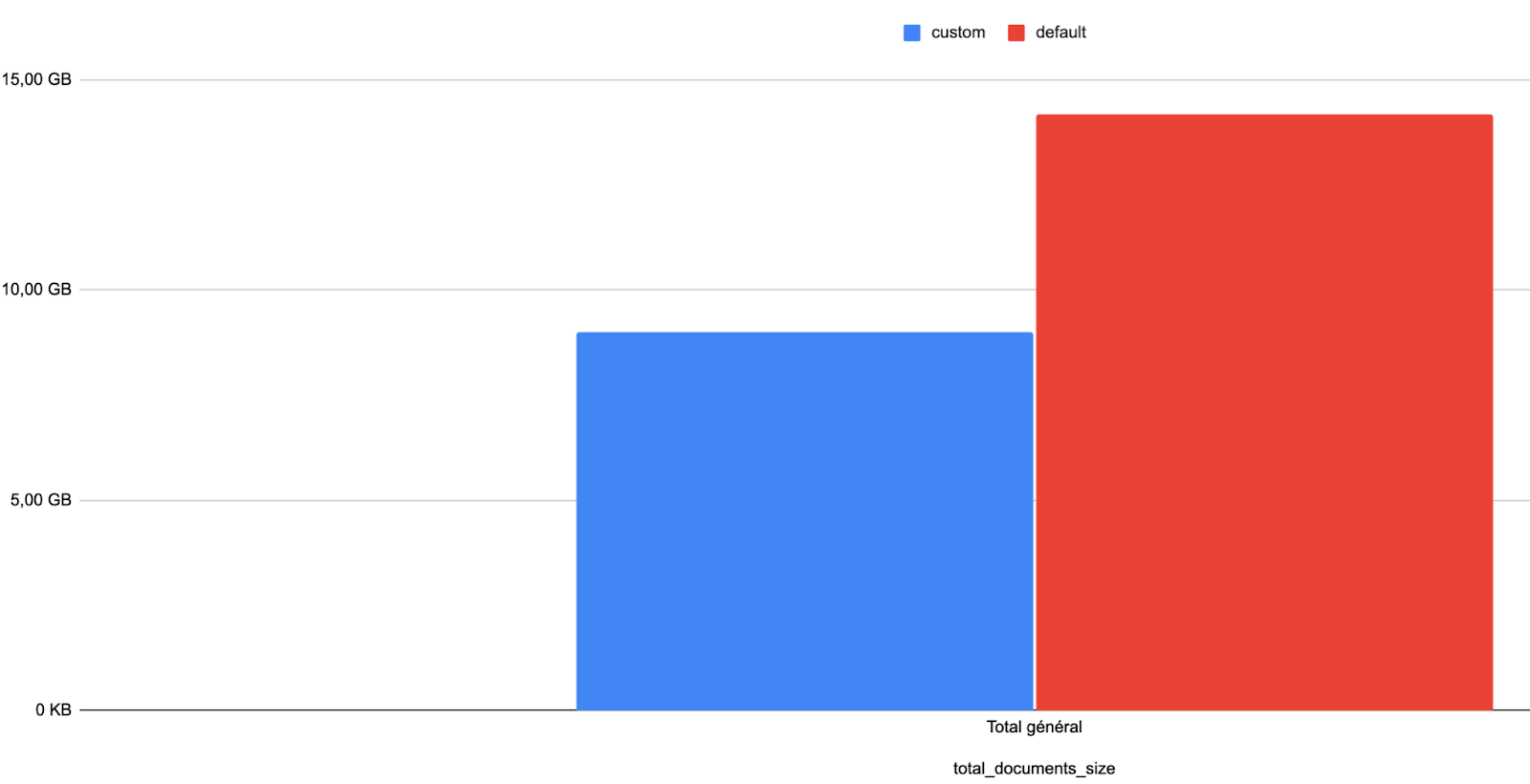
自定义设置(蓝色)和默认设置(红色)下的数据库大小
了解 Meilisearch 能为您的业务带来什么
目前就这些!我们介绍了加快索引过程的最佳实践。您知道这些技巧吗?遵循它们之后,您是否注意到索引速度有差异?在我们的 Discord 上分享您的经验吧!
您的反馈对我们改进 Meilisearch 至关重要!我再怎么强调也不为过,我永远不会厌倦重复这一点,因为这是事实。我们的社区与我们一起构建了 Meilisearch,并继续帮助我们塑造它。
GitHub 上的问题或产品讨论,我们的路线图,我们的Discord 服务器……无论在哪里,无论如何,我们都想听到您的声音!

Meilisearch 通过二进制量化将嵌入索引速度提高 7 倍
通过使用向量存储 Arroy 实现二进制量化,已显著减少大型嵌入的磁盘空间使用和索引时间,同时保持了搜索的相关性和效率。


Meilisearch 太慢了
在这篇博客文章中,我们探讨了 Meilisearch 文档索引器所需的改进。我们将讨论当前的索引引擎、其缺点以及优化性能的新技术。